1. What is SQL Server?
Ans: SQL SERVER is a relational database management system (RDBMS) developed by Microsoft. It is primarily designed and developed to compete with MySQL and Oracle database.
SQL Server supports ANSI SQL, which is the standard SQL (Structured Query Language) language. However, SQL Server comes with its own implementation of the SQL language, T-SQL
2. What are primary keys and foreign keys?
Ans: Primary keys are the unique identifiers for each row. They must contain unique values and cannot be null. Due to their importance in relational databases, Primary keys are the most fundamental of all keys and constraints. A table can have only one Primary key. Foreign keys are both a method of ensuring data integrity and a manifestation of the relationship between tables.
3. What's the difference between a primary key and a unique key?
Ans: Both primary key and unique key enforces the uniqueness of the column on which they are defined. But by default primary key creates a clustered index on the column, where are unique creates a nonclustered index by default. Another major difference is that primary key doesn't allow NULLs, but the unique key allows one NULL only.

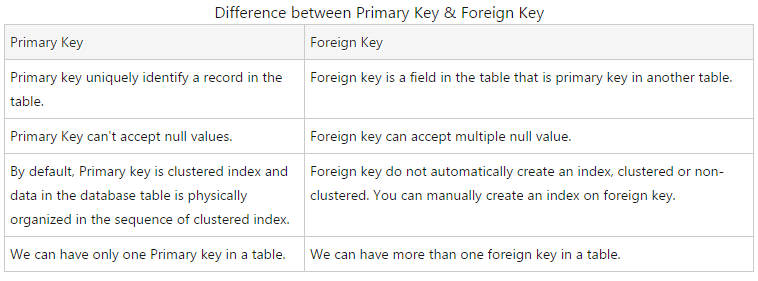
4. What's the difference between a primary key and a foreign Key?
5. What is the difference between a clustered and a non-clustered index?
Ans: 1. A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore the table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
2. A non clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non-clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
6. What is the difference between a HAVING CLAUSE and a WHERE CLAUSE?
Ans: They specify a search condition for a group or an aggregate. But the difference is that HAVING can be used only with the SELECT statement. HAVING is typically used in a GROUP BY clause. When GROUP BY is not used, HAVING behaves like a WHERE clause. Having Clause is basically used only with the GROUP BY function in a query whereas WHERE Clause is applied to each row before they are part of the GROUP BY function in a query.
OR
HAVING is only for conditions involving aggregates used in conjunction with the GROUP BY clause. eg. COUNT, SUM, AVG, MAX, MIN. WHERE is for any non-aggregate conditions.
Though the HAVING clause specifies a condition that is similar to the purpose of a WHERE clause, the two clauses are not interchangeable. Listed below are some differences to help distinguish between the two:
1. The WHERE clause specifies the criteria which individual records must meet to be selected by a query. It can be used without the GROUP BY clause. The HAVING clause cannot be used without the GROUP BY clause.
2. The WHERE clause selects rows before grouping. The HAVING clause selects rows after grouping.
3. The WHERE clause cannot contain aggregate functions. The HAVING clause can contain aggregate functions.
for Example: if for a "Select" statement we use the "where" clause then the result based on the "where" condition results and then we can use the "group by" clause to arrange in some order, Now if we want to impose the condition on that group then we use "having" clause.
Most of the time you will get the same result with Where or Having.
The below given two SQL command produces the same result set.
1) Select Empid , SUM(Salary) From tblEmployeedetails Group By DeptId having Deptid='D0000234'
2) Select Empid , SUM(Salary) From tblEmployeedetails Where Deptid='D0000234' Group By DeptId
7. Can a stored procedure call itself or recursive stored procedure? How much level SP nesting is possible?
Ans: Yes. Because Transact-SQL supports recursion, you can write stored procedures that call themselves. Recursion can be defined as a method of problem solving wherein the solution is arrived at by repetitively applying it to subsets of the problem. A common application of recursive logic is to perform numeric computations that lend themselves to repetitive evaluation by the same processing steps. Stored procedures are nested when one stored procedure calls another or executes managed code by referencing a CLR routine, type, or aggregate. You can nest stored procedures and managed code references up to 32 levels.
8. What is Table-Valued Functions?
Ans: User-defined functions that return a table data type can be powerful alternatives to views. These functions are referred to as table-valued functions. A table-valued user-defined function can be used where table or view expressions are allowed in Transact-SQL queries. While views are limited to a single SELECT statement, user-defined functions can contain additional statements that allow more powerful logic than is possible in views.
For Eg:-
(I) CREATEFUNCTIONGetAllEmployees()
RETURNSTABLE
AS
RETURN
(SELECTemp_id,emp_name,mgr_id
FROMtbl_emp)
GO
select*fromGetAllEmployees()
(II) CREATEFUNCTIONGetEmployees(@emp_idint)
RETURNSTABLE
AS
RETURN
(
SELECTemp_id,emp_name,mgr_id
FROMtbl_emp
whereemp_id=@emp_id
)
GO
SELECT*FROMGetEmployees('2')
9. Scalar-Valued Functions?
Ans: A scalar-valued function (SVF) is a user-defined function (UDF) that returns a single value. Scalar-valued functions can take arguments and return values of any scalar data type supported by SQL Server except row version, text, ntext, image, timestamp, table, or cursor.
An SVF is implemented as a method of a class in a .NET Framework assembly. The return value of the method must be compatible with the SQL Server data type that the method returns.
10. Difference between table-valued function and view in SQL server with example?
Ans: A parameterless inline TVF and a non-materialized View are very similar. A few functional differences that spring to mind are below.
Views
- Accepts Parameters - No
- Expanded out by Optimiser - Yes
- Can be Materialized (indexed) - Yes
- Is Updatable - Yes
- Can contain Multiple Statements - No
- Can have triggers - Yes
- Can use side-effecting operator - Yes
MultiStatement TVFs
- Accepts Parameters - Yes
- Expanded out by Optimiser - No
- Can be Materialized (indexed) - No
- Is Updatable - No
- Can contain Multiple Statements - Yes
- Can have triggers - No
- Can use side-effecting operator - No
11. What is SQL Injection?
Ans: The word Injection means to inject something in your system and SQL Injection means injecting some SQL in your database system for hacking it to steal your information such as Username and Passwords for login authentication or causing harm to your system by deleting data or dropping tables.
eg: select * from MyTable where Email='' or 1=1--'and Password=''
12. How to Prevent SQL Injection?
Ans: ASP.NET provides us a beautiful mechanism for prevention against SQL injection. There are some thumb rules that should be followed in order to prevent injection attacks on our websites.
User input should never be trusted. It should always be validated
Dynamic SQL should never be created using string concatenations.
Always prefer using Stored Procedures.
If dynamic SQL is needed it should be used with parametrized commands.
All sensitive and confidential information should be stored in encrypted.
The application should never use/access the DB with Administrator privileges.
13. What are TRIGGERS in SQL Server?
Ans: A trigger is a special kind of stored procedure that automatically executes when an event occurs in the database server. DML triggers execute when a user tries to modify data through a data manipulation language (DML) event. DML events are INSERT, UPDATE, or DELETE statements on a table or view.
Types of Triggers: -
1. After Trigger (using FOR/AFTER CLAUSE)
This type of trigger fires after SQL Server finish the execution of the action successfully that fired it.
Example: If you insert record/row in a table then the trigger related/associated with the insert event on this table will fire only after the row passes all the constraints, like as primary key constraint, and some rules. If the record/row insertion fails, SQL Server will not fire the After Trigger.
2. Instead of Trigger (using INSTEAD OF CLAUSE)
This type of trigger fires before SQL Server starts the execution of the action that fired it. This is different from the AFTER trigger, which fires after the action that caused it to fire. We can have an INSTEAD OF insert/update/delete trigger on a table that is successfully executed but does not include the actual insert/update/delete to the table.
Example: If you insert a record/row in a table then the trigger related/associated with the insert event on this table will fire before the row passes all the constraints, such as primary key constraint and some rules. If the record/row insertion fails, SQL Server will fire the Instead of Trigger.
SELECT State, Count(CustomerID) As NumberOfCustomers
FROM Customers
WHERE State <> "NY"
GROUP BY State
HAVING Count(CustomerID) >10
ORDER BY Count(CustomerID) DESC
14. What is Indexing?
Ans:- Indexing provides a way to improve the performance of your data access queries. Suppose you have a table with different identifying columns. Putting an index on each column, or combinations of columns that are queried together will improve your response time.
1) Clustered
An index defined as being clustered defines the physical order that the data in a table is stored. Only one cluster can be defined per table. So it can be defined as:
Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table because the data rows themselves can be sorted in only one order.
The only time the data rows in a table are stored in sorted order is when the table contains a clustered index. When a table has a clustered index, the table is called a clustered table. If a table has no clustered index, its data rows are stored in an unordered structure called a heap.
2) Non-Clustered
As a non-clustered index is stored in a separate structure to the base table, it is possible to create the non-clustered index on a different file group to the base table. So it can be defined as:
Non-Clustered indexes have a structure separate from the data rows. A non-clustered index contains the non-clustered index key values and each key-value entry has a pointer to the data row that contains the key value.
The pointer from an index row in a non-clustered index to a data row is called a row locator. The structure of the row locator depends on whether the data pages are stored in a heap or a clustered table. For a heap, a row locator is a pointer to the row. For a clustered table, the row locator is the clustered index key.
You can add nonkey columns to the leaf level of the Non-Clustered index to by-pass existing index key limits, 900 bytes and 16 key columns, and execute fully covered, indexed, queries.
15. What is Normalization in SQL?
Ans: Normalization is the process of efficiently organizing data in a database. There are two goals of the normalization process: eliminating redundant data (for example, storing the same data in more than one table) and ensuring data dependencies make sense (only storing related data in a table). Both of these are worthy goals as they reduce the amount of space a database consumes and ensure that data is logically stored. There are several benefits of using Normalization in Database.
Benefits:
Eliminate data redundancy
Improve performance
Query optimization
Faster update due to less number of columns in one table
Index improvement
16. What is CHECK constraint?
Ans: A CHECK constraint can be applied to a column in a table to limit the values that can be placed in a column. Check constraint is to enforce integrity.
17. What are scheduled tasks in SQL Server?
Scheduled tasks or jobs are used to automate processes that can be run on a scheduled time at a regular interval. This scheduling of tasks helps to reduce human intervention during the night time and feed can be done at a particular time. User can also order the tasks in which it has to be generated.
18. What is COALESCE in SQL Server?
COALESCE is used to return the first non-null expression within the arguments. This function is used to return a non-null from more than one column in the arguments.
19. How exceptions can be handled in SQL Server Programming?
Exceptions are handled using TRY—-CATCH constructs and it is handles by writing scripts inside the TRY block and error handling in the CATCH block.
20. What is the purpose of FLOOR function?
FLOOR function is used to round up a non-integer value to the previous least integer. Example is given
Returns 6.
21. Can we check locks in database? If so, how can we do this lock check?
Yes, we can check locks in the database. It can be achieved by using in-built stored procedure called sp_lock.
22. What is the use of SIGN function?
SIGN function is used to determine whether the number specified is Positive, Negative and Zero. This will return +1,-1 or 0.
23. What is a Trigger?
Triggers are used to execute a batch of SQL code when insert or update or delete commands are executed against a table. Triggers are automatically triggered or executed when the data is modified. It can be executed automatically on insert, delete and update operations.
24. What are the types of Triggers?
There are four types of triggers and they are:
Insert
Delete
Update
Instead of
25. What is an IDENTITY column in insert statements?
IDENTITY column is used in table columns to make that column as Auto incremental number or a surrogate key.
26. What is Bulkcopy in SQL?
Bulkcopy is a tool used to copy large amount of data from Tables. This tool is used to load large amount of data in SQL Server.
27. What will be query used to get the list of triggers in a database?
Query to get the list of triggers in database-
28. What is the difference between UNION and UNION ALL?
UNION statement is mainly used to combine the tables including the duplicate rows and UNION ALL combine but does not look for duplicate rows. With this, UNION ALL will be very faster than UNION statements.
29. How Global temporary tables are represented and its scope?
Global temporary tables are represented with ## before the table name. Scope will be the outside the session whereas local temporary tables are inside the session. Session ID can be found using @@SPID.
30. What are the differences between Stored Procedure and the dynamic SQL?
Stored Procedure is a set of statements that is stored in a compiled form. Dynamic SQL is a set of statements that dynamically constructed at runtime and it will not be stored in a Database and it simply execute during run time.
31. What is Collation?
Collation is defined to specify the sort order in a table. There are three types of sort order –
Case sensitive
Case Insensitive
Binary
32. How can we get count of the number of records in a table?
Following are the queries can be used to get the count of records in a table –
33. What is the command used to get the version of SQL Server?
is used to get the version of SQL Server.
34. What is UPDATE_STATISTICS command?
UPDATE_STATISTICS command is used to update the indexes on the tables when there is a large amount of deletions or modifications or bulk copy occurred in indexes.
35. What is the use of SET NOCOUNT ON/OFF statement?
By default, NOCOUNT is set to OFF and it returns number of records got affected whenever the command is getting executed. If the user doesn’t want to display the number of records affected, it can be explicitly set to ON- (SET NOCOUNT ON).
36. Which SQL server table is used to hold the stored procedure scripts?
Sys.SQL_Modules is a SQL Server table used to store the script of stored procedure. Name of the stored procedure is saved in the table called Sys.Procedure.
37. What are Magic Tables in SQL Server?
Insert and Delete tables are created when the trigger is fired for any DML command. Those tables are called Magic Tables in SQL Server. These magic tables are used inside the triggers for data transaction.
38. What is the difference between SUBSTR and INSTR in the SQL Server?
The SUBSTR function is used to return specific portion of string in a given string. But, INSTR function gives character position in a given specified string.
Gives result as Smi
Gives 3 as result as I appears in 3rd position of the string
39. What is the use of =,==,=== operators?
= is used to assign one value or variable to another variable. == is used for comparing two strings or numbers. === is used to compare only string with the string and number with numbers.
40. What is ISNULL() operator?
ISNULL function is used to check whether value given is NULL or not NULL in sql server. This function also provides to replace a value with the NULL.
41. What is the use of FOR Clause?
FOR clause is mainly used for XML and browser options. This clause is mainly used to display the query results in XML format or in browser.
42. What will be the maximum number of index per table?
100 Index can be used as maximum number per table. 1 Clustered Index and 999 Non-clustered indexes per table can be used in SQL Server.
43. What is the difference between COMMIT and ROLLBACK?
Every statement between BEGIN and COMMIT becomes persistent to database when the COMMIT is executed. Every statement between BEGIN and ROOLBACK are reverted to the state when the ROLLBACK was executed.
44. What is the difference between varchar and nvarchar types?
Varchar and nvarchar are same but the only difference is that nvarhcar can be used to store Unicode characters for multiple languages and it also takes more space when compared with varchar.
45. What is the use of @@SPID?
A @@SPID returns the session ID of the current user process.
46. What is the command used to Recompile the stored procedure at run time?
Stored Procedure can be executed with the help of keyword called RECOMPILE.
Example
Or we can include WITHRECOMPILE in the stored procedure itself.
47. How to delete duplicate rows in SQL Server?
Duplicate rows can be deleted using CTE and ROW NUMER feature of SQL Server.
48. Where are SQL Server user names and passwords stored in SQL Server?
User Names and Passwords are stored in sys.server_principals and sys.sql_logins. But passwords are not stored in normal text.
49. What is the difference between GETDATE and SYSDATETIME?
Both are the same but GETDATE can give time till milliseconds and SYSDATETIME can give precision till nanoseconds. SYSDATE TIME is more accurate than GETDATE.
50. How data can be copied from one table to another table?
INSERT INTO SELECT
This command is used to insert data into a table which is already created.
SELECT INTO
This command is used to create a new table and its structure and data can be copied from existing table.
51. What is TABLESAMPLE?
TABLESAMPLE is used to extract samples of rows randomly that are all necessary for the application. The sample rows taken are based on the percentage of rows.
52. Which command is used for user-defined error messages?
RAISEERROR is the command used to generate and initiates error processing for a given session. Those user defined messages are stored in sys.messages table.
53. What do mean by XML Datatype?
XML data type is used to store XML documents in the SQL Server database. Columns and variables are created and store XML instances in the database.
54. What is CDC?
CDC is abbreviated as Change Data Capture which is used to capture the data that has been changed recently. This feature is present in SQL Server 2008.
55. What is SQL injection?
SQL injection is an attack by malicious users in which malicious code can be inserted into strings that can be passed to an instance of SQL server for parsing and execution. All statements have to check for vulnerabilities as it executes all syntactically valid queries that it receives.
Even parameters can be manipulated by the skilled and experienced attackers.
56. What are the methods used to protect against SQL injection attack?
Following are the methods used to protect against SQL injection attack:
Use Parameters for Stored Procedures
Filtering input parameters
Use Parameter collection with Dynamic SQL
In like clause, user escape characters
57. What is Filtered Index?
Filtered Index is used to filter some portion of rows in a table to improve query performance, index maintenance and reduces index storage costs. When the index is created with WHERE clause, then it is called Filtered Index
58. What is SQL Server Isolation?
Ans:
READ UNCOMMITTED: A query in the current transaction can read data modified within another transaction but not yet committed. The database engine does not issue shared locks when Read Uncommitted is specified, making this the least restrictive of the isolation levels. As a result, it’s possible that a statement will read rows that have been inserted, updated or deleted, but never committed to the database, a condition known as dirty reads. It’s also possible for data to be modified by another transaction between issuing statements within the current transaction, resulting in no repeatable reads or phantom reads.
READ COMMITTED: A query in the current transaction cannot read data modified by another transaction that has not yet committed, thus preventing dirty reads. However, data can still be modified by other transactions between issuing statements within the current transaction, so no repeatable reads and phantom reads are still possible. The isolation level uses shared locking or row versioning to prevent dirty reads, depending on whether the READ_COMMITTED_SNAPSHOT database option is enabled. Read Committed is the default isolation level for all SQL Server databases.
REPEATABLE READ: A query in the current transaction cannot read data modified by another transaction that has not yet committed, thus preventing dirty reads. In addition, no other transactions can modify data being read by the current transaction until it completes, eliminating no repeatable reads. However, if another transaction inserts new rows that match the search condition in the current transaction, in between the current transaction accessing the same data twice, phantom rows can appear in the second read.
SERIALIZABLE: A query in the current transaction cannot read data modified by another transaction that has not yet committed. No other transaction can modify data being read by the current transaction until it completes, and no other transaction can insert new rows that would match the search condition in the current transaction until it completes. As a result, the Serializable isolation level prevents dirty reads, no repeatable reads, and phantom reads. However, it can have the biggest impact on performance, compared to the other isolation levels.
SNAPSHOT: A statement can use data only if it will be in a consistent state throughout the transaction. If another transaction modifies data after the start of the current transaction, the data is not visible to the current transaction. The current transaction works with a snapshot of the data as it existed at the beginning of that transaction. Snapshot transactions do not request locks when reading data, nor do they block other transactions from writing data. In addition, other transactions writing data do not block the current transaction for reading data. As with the Serializable isolation level, the Snapshot level prevents dirty reads, no repeatable reads and phantom reads. However, it is susceptible to concurrent update errors. (not ANSI/ISO SQL standard)
59. What is temporary table in sql?
SQL Server provides the concept of temporary table which helps the developer in a great way. These tables can be created at runtime and can do the all kinds of operations that one normal table can do. But, based on the table types, the scope is limited. These tables are created inside tempdb database.
Different Types of Temporary Tables
SQL Server provides two types of temp tables based on the behavior and scope of the table. These are:
Local Temp Table
Global Temp Table
Local Temp Table
Local temp tables are only available to the current connection for the user; and they are automatically deleted when the user disconnects from instances. Local temporary table name is stared with hash ("#") sign.
Global Temp Table
Global Temporary tables name starts with a double hash ("##"). Once this table has been created by a connection, like a permanent table it is then available to any user by any connection. It can only be deleted once all connections have been closed.
60. What is CTE in SQL SERVER?
Ans: Specifies a temporary named result set, known as a common table expression (CTE). This is derived from a simple query and defined within the execution scope of a single SELECT, INSERT, UPDATE, or DELETE statement. This clause can also be used in a CREATE VIEW statement as part of its defining SELECT statement. A common table expression can include references to itself. This is referred to as a recursive common table expression.
For Eg:-
With T(Address, Name, Age) --Column names for Temporary table
AS
(
SELECT A.Address, E.Name, E.Age from Address A
INNER JOIN EMP E ON E.EID = A.EID
)
SELECT * FROM T --SELECT or USE CTE temporary Table
WHERE T.Age > 50
ORDER BY T.NAME
When to use Common table expression (CTE):-
One example, if you need to reference/join the same data set multiple times you can do so by defining a CTE. Therefore, it can be a form of code re-use.
An example of self-referencing is recursion: Recursive Queries Using CTE
For exciting Microsoft definitions Taken from Books Online:
A CTE can be used to:
Create a recursive query. For more information, see Recursive Queries Using Common Table Expressions.
Substitute for a view when the general use of a view is not required; that is, you do not have to store the definition in metadata.
Enable grouping by a column that is derived from a scalar sub select, or a function that is either not deterministic or has external access.
Reference the resulting table multiple times in the same statement.
http://www.codeproject.com/Articles/265371/Common-Table-Expressions-CTE-in-SQL-SERVER
61. Can we use ORDER BY Clause in SQL server subquery?
Ans: If subquery return one value then we can use otherwise didn’t use.
select * from (SELECT TOP 100 PERCENT COUNT(1) from Salary order by Name desc )
62. Tables − In the relational data model, relations are saved in the format of Tables. This format stores the relationships among entities. A table has rows and columns, where rows represent records and columns represent the attributes.
Tuple − A single row of a table, which contains a single record for that relation is called a tuple.
63. What is Stuff?
Ans: The Stuff string function deletes a sequence of characters from a source string and then inserts a string into another string.
OR
The STUFF function inserts a string into another string. It deletes a specified length of characters in the first string at the start position and then inserts the second string into the first string at the start position. For more detail click below link
Syntax
Stuff (Source_string, start, length, replace string)
Parameters Arguments
Source_String:
Source_String is characters data. It can be s constant, variable, column or either characters or binary data.Start:
It specifies the location to start deleting and inserting strings.Length:
It specifies the number of characters that can be deleted in the source string.Replace:
It can replace characters of the start and length of that character.
64. What is a Cursor?
Ans: Cursor is a database object used by applications to manipulate data in a set on a row-by-row basis, instead of the typical SQL commands that operate on all the rows in the set at one time.
In order to work with a cursor we need to perform some steps in the following order:
Declare cursor
Open cursor
Fetch row from the cursor
Process fetched row
Close cursor
Deallocate cursor
65. SQL Server query optimization techniques?
Ans:
1. Define business requirements first
2. SELECT fields instead of using SELECT *
3. Avoid SELECT DISTINCT
4. Create joins with INNER JOIN (not WHERE)
5. Use WHERE instead of HAVING to define filters
6. Use wildcards at the end of a phrase only
7. Use LIMIT to sample query results
No comments:
Post a Comment